
The Rise of Data Products: How Engineering Will Evolve Beyond Pipelines by 2028
Data is being fundamentally reimagined before our eyes. It’s no longer a byproduct. It’s becoming the core of business operations. The shift from data pipelines to data products – fueled by AI, data democratization, and scalable frameworks — is transforming how organizations operate.
This guide is your starting point to understand the transition, implement data products, and unlock measurable business value in no time.
The Data Engineering Landscape Today (Hard Truths + Real Picture)
Having data doesn’t necessarily translate into value.
In fact, most data engineering teams spend 70-80% of their time babysitting pipelines that keep breaking, rely on tribal knowledge, and deliver value to maybe five people in the analytics department.
The problem isn’t with data engineers. It’s with the model they work on.
Gone are the days when the focus was “how can we move data from Point A to Point B?.” Today, teams are asking “how can we deliver data that solves business problems with a layer of personalization built in.”
That’s the real paradigm shift underway, and every room is abuzz with one technology and its massive promise: Data Products
Data products are turning data engineering inside out: moving teams from maintaining fragile pipelines to delivering reusable, business-ready insights. In this guide, you’ll learn what data products are, why they’re crucial for AI and analytics, and how they create measurable outcomes for every department.
Skip the Theory and Start Doing.
What are Data Products?
A data product is a self-contained, discoverable, and reliable reservoir of information that someone can pick up and get value from immediately. It has troves of polished, usable insights teams can act on, contrary to a data pipeline that involves a series of actions to create the same output.
What truly pulls people in is the word “product,” signifying the change in the whole mindset. In the new scheme of things, data isn’t something that gets passed on from one system to another. Instead, it’s looked at as a product – packaged, reusable, and valuable.
With a data product, you’re thinking like a product manager and asking the right questions:
- Who needs this data?
- What problem does it solve?
- Will people actually use it?
- How do we make it better and more accessible over time?
When teams begin to think like that, data stops being a byproduct of operations and starts becoming an asset a business leans on every data to stay ahead of the game.

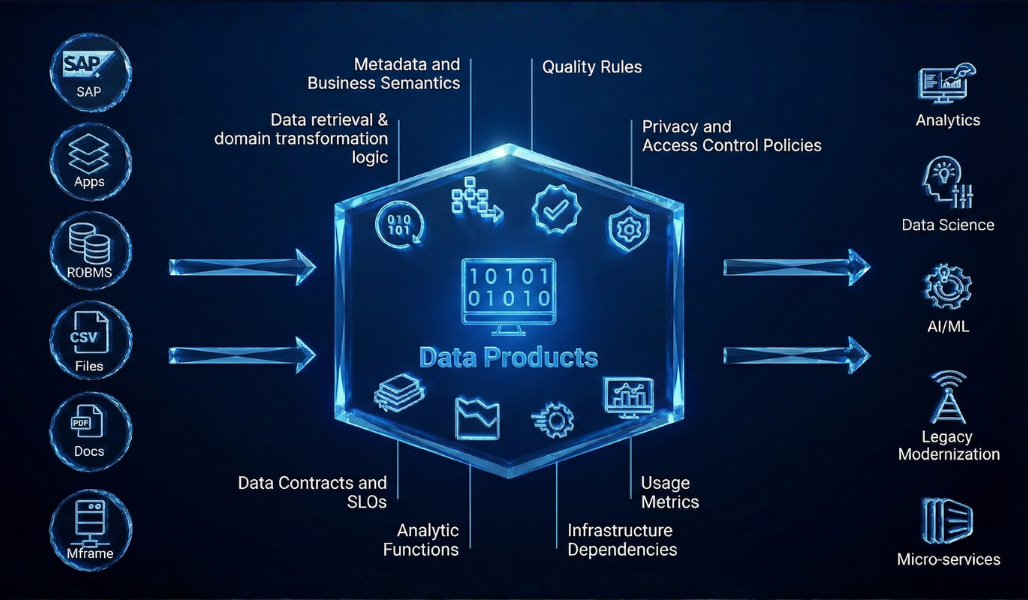
Core Components of a Data Product
What actually makes up a data product? It’s more than just a dataset sitting in a warehouse. A data product consists:
- Data, but not the kind that’s lacking definite structure. This data is thoughtfully curated, cleaned, and structured for immediate value generation.
- Metadata telling where the data streams come from, how fresh the information is., what it essentially has, and who’s responsible for or set to benefit from it.
- Logic and Code that refers to transformations, business rules, and ML scoring models, turning raw inputs into actionable insights. This is the backstage machinery that gives the product its value.
- Governance and policies built right in. Access controls, privacy protections, compliance rules, and data quality standards aren’t bolted on afterward.
- Delivery interfaces that make the product accessible. This could be APIs, SQL views, dashboards, or embedded analytics. The interface matches how users actually want to consume the data.
Data Pipelines vs. Data Products
This is where people often get confused, so let’s be clear about the distinction.
Data pipelines are the underlying technical infrastructure focused on moving and processing data. They answer the question “How.” How will teams extract the data? How will they curate and analyze the data? How will they make it accessible?
ETL is at the core of many data pipelines since it’s a proven method for organizing data for analysis. It extracts information from various sources, transforms it into a usable format, and loads it into a central destination. And, that’s where the entire responsibility ends.
Data products, on the other hand, are business assets, allowing access to data as a user-facing deliverable that adds continuous value to the business. They focus on the question “What.” What problem will we solve? What decisions will the data enable? What outcomes will we achieve?
Unlike pipelines that focus on transport, data products focus on delivering value and outcomes – faster. By sharing insights in a polished, discoverable format, it empowers teams to quickly scale, pivot, and accelerate while achieving a competitive advantage.
Long story short: one is inside-out (technical specifications). The other is outside-in (user needs and business value).
Check the comparison table outlining Data Pipelines and Data Products.
| Aspect | Traditional Pipelines | Data Products |
|---|---|---|
| Focus | Technical flow and data movement – emphasis on ETL logic, transformations, and system integrations | Business outcomes and user needs – designed to solve specific problems and deliver measurable value |
| Ownership | Centralized engineering teams who build and maintain all data workflows | Distributed domain teams who own data relevant to their business area (marketing, finance, operations) |
| Reusability | Limited to specific use cases – often rebuilt from scratch for similar needs across teams | Intentionally designed for reuse across multiple applications, users, and business functions |
| Documentation | Technical specifications, code comments, and pipeline diagrams focused on “how it works” | Comprehensive business context including what the data means, who should use it, and how to interpret results |
| Quality | Best effort based on available time and resources – reactive fixes when issues arise | SLA-driven with defined guarantees for accuracy, completeness, freshness, and uptime |
| Users | Data professionals (engineers, analysts, scientists) who understand technical systems | Broad business stakeholders including executives, marketers, sales teams, and operations managers |
| Success Metrics | Pipeline uptime, data freshness, processing time | User adoption rates, business KPI impact, decision-making speed improvements |
| Discovery | Tribal knowledge – you need to know who built it to find it | Cataloged and searchable with metadata, making it easy to find and understand |
| Governance | Applied inconsistently, often as an afterthought | Built-in access controls, lineage tracking, and compliance from day one |
| Evolution | Changes require deep technical knowledge and risk breaking dependencies | Product roadmap with versioning, backward compatibility, and clear communication of changes |
Benefits of Data Products for Businesses
Companies leveraging data products see faster decisions, higher trust in analytics, and exponential efficiency gains. Beyond pipelines, these products accelerate AI adoption, operational intelligence, and innovation, turning data into a strategic business asset. We’ve outlined the top five benefits companies stand to gain with this transition.
First, speed improves. Teams that operate with mature data products make decisions at speed. There’s no waiting around or drawn-out steps. Data’s already there – ready and reliable.
Second, trust increases. When data products come with clear metrics and documented lineage, people actually believe the numbers they’re looking at. Remember, data trust issues cost organizations an estimated $3.1 trillion annually in bad decisions and rework.
Third, efficiency catalyzes. With a single window of polished, neat, and reusable chunks of information, the back-and-forth for reliable data stops. With data products, you can serve hundreds of use cases across multiple teams. You’re building once and reusing many times, rather than creating redundant pipelines for every slightly different need.
Fourth, innovation maximizes. When high-quality data is easy to reach, teams experiment more, analysts move faster, and AI models become easier to operationalize. Good data becomes fuel, removing roadblocks to innovation and creating a culture of unbridled innovation.
Fifth and the last, decision-making strengthens. By offering reusable, high-quality, and trusted information, data products help unlock a 360-degree visibility into operational bottomlines as well as target markets. Companies stay ahead by identifying patterns and keep creating new opportunities for growth.
Other benefits of data products include lower costs, better AI/ML model performance, and new revenue opportunities through data monetization.
Sitting on analytics? You could be sitting on gold.
How Data Products Are Transforming Business Experiences?
Data products move beyond dashboards and reports. They act as the invisible scaffolding that redefines user experiences, operational readiness, and even factors impacting business strategy. Here’s how these new-generation tools are bringing a seismic shift.
- Experiences Become Hyper-Adaptive, Not Just Personalized
Personalization sits at the epicenter of data products. With actionable, context-aware insights, companies unlock the real edge: adaptive experiences that anticipate needs. Examples include enterprise collaboration platforms embedding “micro-productivity nudges” powered by data products, suggesting next steps in workflows or alerting users to overlooked opportunities. This isn’t just about recommendations; it’s about minimizing cognitive load while maximizing value. For B2B users, this can translate into weeks saved per quarter across complex operations.
- Operational Intelligence Weaved into Every Layer
Data products don’t just reveal chunks of actionable information. They reimagine bottom-up operations. Industrial IoT platforms, for instance, are now using data products not only for predictive maintenance but also for dynamic resource allocation. Sensors in manufacturing lines feed data into a product that doesn’t just forecast but also suggests optimal production sequences, balancing throughput, energy consumption, and safety risk. This shift converts data from a reporting tool into a decision-making engine, creating measurable efficiency gains.
- Experience-Driven Risk Management
Rather than relying on reactive alerts, data products enable businesses to design risk strategies that are experiential. By combining real-time behavioral signals with relevant contextual data, companies can deliver subtle prompts or proactive recommendations that prevent missteps without requiring manual intervention, turning risk mitigation into a seamless, user-centric experience.
- Data as a Design Element of Product Strategy
Forward-looking companies treat data products as strategic design levers. By surfacing hidden patterns and insights, data products inform product roadmaps, reveal new opportunities, and guide decisions that go beyond immediate user feedback. In this way, they not only enhance current experiences but also shape future offerings actively. For example, an eCommerce brand might notice when people usually come back and where they tend to drop off in the journey. With that simple pattern, the team can design a smoother replenishment flow that feels intuitive, even though no customer ever asked for it directly.
- Human-Centric Insights That Mitigate Inefficiencies
The most undervalued aspect of data products is their ability to expose operational and experiential blind spots that humans cannot see on their own. For example, hospital workflow platforms can surface bottlenecks invisible to staff—like subtle delays in lab results that cascade into patient care slowdowns. The insights are granular and actionable, enabling interventions that improve outcomes at scale.
Why Now? The Forces Driving the Data Product Revolution
This shift isn’t happening in a vacuum. Several powerful forces are converging to make the product approach not just beneficial but necessary.
1. The AI/ML Imperative
Most AI initiatives fail because of unreliable or inconsistent data. AI models require high-quality, structured, and reproducible datasets, along with reliable pipelines and continuous feedback loops. Traditional ad-hoc engineering simply cannot scale to meet these demands.
Data products address this problem. By packaging data as reusable, governed assets, data scientists can train models faster, detect drift earlier, and deploy with confidence. The result: AI projects that deliver measurable outcomes instead of costly failures.
2. Data Democratization & Self-Service Analytics
Business users shouldn’t wait days for data they need to make decisions. Traditional processes often create bottlenecks, with teams drowning in one-off requests.
Data products bring in a refreshing change. They enable self-service access to pre-built, trusted datasets. Marketing gets customer segmentation products, Finance gets revenue attribution products, Operations gets supply chain visibility products. The data team shifts from firefighting to curating a portfolio of high-value products, while business users gain instant access to accurate, actionable data.
3. The Data Mesh Architecture Movement
Centralized data teams can’t scale effectively in large, complex organizations. They often lack domain-level insight, creating bottlenecks and limiting impact.
Data mesh, as a decentralized approach, empowers domain teams to own and manage their data products, while still adhering to organization-wide standards. Each product is discoverable, governed, and reusable. Domain experts maintain ownership and accountability, making data both reliable and actionable across the enterprise.
4. Regulatory & Governance Pressures
Data privacy and compliance requirements are growing increasingly complex and cost-consuming. Traditional pipelines make it hard to track lineage, enforce access controls, or ensure accountability.
Data products embed governance from day one. Access is controlled at the product level, lineage is documented, and quality metrics are tracked continuously. Businesses can operate confidently, reduce regulatory risk, and build trust with customers.
5. Economic Efficiency
Redundant pipelines waste time, money, and resources. Multiple teams often recreate similar data transformations, leading to higher maintenance costs and inconsistent outputs.
The payoff of data products is massive. Teams build once, reuse many times. They replace brittle, undocumented pipelines with reliable, governed assets. They shift resources from reactive maintenance to proactive innovation. Plus, they are able to drive 10x productivity improvements and accelerate business outcomes.
Data Engineering Landscape of the Future (Predictions + Trends)
Looking ahead to 2028, several trends will reshape how organizations build and operate data products.
- AI will automate large portions of data engineering work
AI-powered tools will generate pipeline code, automatically optimize queries, predict and prevent failures, and even suggest data product improvements based on usage patterns. Data engineers will spend less time on repetitive coding and more time on strategic product decisions. Expect 80% of routine data engineering tasks to involve AI assistance by 2028.
- Real-time will become the default
Batch processing won’t disappear, but real-time streaming architectures will handle the majority of enterprise workloads. Business users increasingly expect data to be current within minutes or seconds, not hours or days. Technologies like Apache Kafka, Flink, and real-time data warehouses like Snowflake’s continuous data pipelines are making this practical at scale.
- Data mesh will go mainstream
The centralized data warehouse won’t vanish, but it will be complemented by distributed data products owned by domain teams. Organizations will adopt federated governance models that balance autonomy with consistency. Expect 50% of large enterprises to implement some form of data mesh architecture.
- DataOps practices will mature
Continuous integration, automated testing, version control, and observability (once hallmarks of software engineering) will become baseline expectations in data engineering. Teams will confidently release data products multiple times a day, backed by robust testing and seamless rollback options.
- The semantic layer will see a renaissance
Organizations are tired of maintaining dozens of slightly different definitions for the same business metric. Leaders find the whole exercise tedious and honestly, highly resource-intensive. With data products taking a centerstage, universal semantic layers that define metrics once and serve them everywhere will gain widespread adoption, powered by tools like dbt metrics, Cube, and native data platform capabilities.
- Composable architectures will dominate
Instead of monolithic platforms, organizations will leverage the power of composable architectures. They will mix-and-match best-of-breed tools connected through standard interfaces and formats. This modularity stimulates innovation and reduces vendor lock-in.
- Synthetic data will proliferate
Privacy concerns, data scarcity, and quality issues are driving rapid growth in synthetic data generation. By 2028, the majority of AI training data will be synthetic, generated from existing data products using advanced techniques.
- Sustainability will influence architecture decisions
As cloud costs and carbon footprints become board-level concerns, data teams will optimize for energy efficiency. Green data engineering practices—like intelligent caching, workload optimization, and efficient storage formats—will reduce costs and environmental impact by 30-40%.
- The modern data stack will consolidate
Today’s landscape of 100+ specialized tools will rationalize into integrated platforms that handle ingestion, transformation, storage, and activation seamlessly. Snowflake, Databricks, and similar platforms are already moving in this direction.
How Infojini Empowers Your Data Product Journey
At Infojini, we’ve been guiding organizations of all sizes through data transformations for years, and we’ve seen firsthand how the shift to data products accelerates business value.
As a Snowflake Partner, we combine platform expertise with proven methodologies and an internal pool of skilled infojinians to help you navigate this evolution. Our approach starts with understanding your business objectives. We ask: What decisions are you trying to enable? What outcomes need to improve? Where are your current data processes creating friction?
From there, we develop a pragmatic roadmap that prioritizes quick wins while building momentum toward long-term transformation. We help you iteratively evolve your data capabilities, delivering value at each stage.
Our data product methodology includes four key phases:
- Assessment and Strategy: We evaluate your current data maturity, identify high-impact use case opportunities, and create a business case with clear ROI projections.
- Foundation Building: We design modern data architectures leveraging the modern platform capabilities, including Snowflake’s. We establish DataOps practices, define team structures, and set up the technical foundation for data products.
- MVP Development: We build your first data product end-to-end, working closely with business stakeholders to ensure it solves real problems. This includes implementation, documentation, training, and establishing feedback loops.
- Scale and Optimize: We help you roll out additional data products, establish centers of excellence, and continuously refine best practices. This ongoing phase focuses on maximizing adoption and demonstrating measurable business impact.
Planning a shift as sweeping as the product-centric data engineering isn’t easy. But you don’t have to figure out it all alone.
Join 50+ companies transforming their data into business products.
Parting Thoughts
For decades, we’ve treated data as a byproduct of operations, something to be collected and stored just in case it might be useful someday. But data is no longer a byproduct. It’s a strategic asset, a competitive differentiator, and increasingly, a core product itself. The companies winning today—Netflix, Amazon, Spotify, Starbucks—treat their data with the same product discipline they apply to customer-facing applications.
By 2028, this product-centric mindset will be table stakes. Organizations that continue building pipelines without thinking about users, value, quality, and accountability will find themselves outpaced by competitors who embrace data products.
The good news? The transition is already underway. The tools, practices, and frameworks exist today. Companies at every maturity level are successfully making this shift, starting with small wins and progressively transforming their data organizations.
- If you’re a data leader, this is your opportunity to drive real transformation.
- If you’re a data engineer, this is your opportunity to expand your impact.
- If you’re a business stakeholder frustrated by slow data access and questionable quality, this is your opportunity to demand better.
The future of data engineering is about creating products that drive decisions, enable innovation, and deliver measurable business impact. The time to start your data product journey is now. The organizations that move decisively today will reap outsized rewards by 2028 and beyond.